


Hey Hari, What is Deep Learning :
Let me answer you, Deep Learning is a subfield of machine learning, the main idea is the same as machine learning which is learning representations from the input data, but deep learning emphasizes learning successive layers of increasingly meaningful data. The word "Successive" is the key. How many layers contribute to a model is called the "Depth" of the model.
In Deep Learning these meaningful representations from the input data are learned via models called "Neural Networks", in which we have layers stacked on each other.
Similar to the Water distillation process :
Yes, you might have known how water purification happens, generally there will be a number of stages or chambers for the input water to pass through at every stage some kind of operation will be performed and water quality will be improved a bit and this continues up to the final stage. In the end, we get the well purified water.
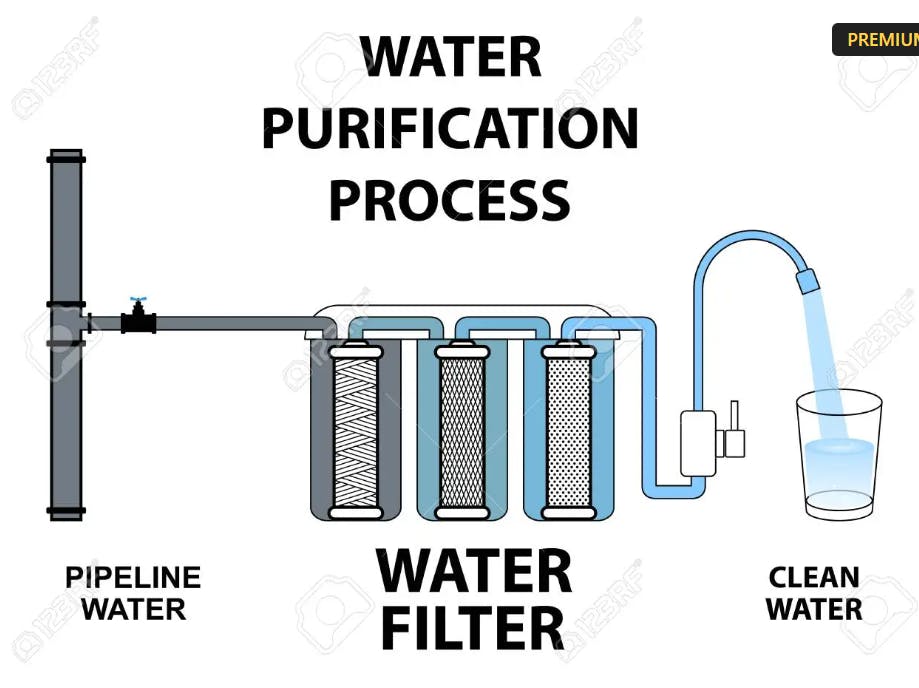
In the similar way, you can think of deep learning as a multistage information-distillation operation, where information goes through successive layers and comes out with meaningful representation.
Okay Hari, Understood the basic intuition behind Deep Learning. But, how the learning happens concretely until the model achieve meangingful representation ???
At this point we know Machine Learning is about mapping inputs(such as images) to targets (such as labels "cats") which is done by observing many examples of input and targets. Deep Neural Networks also do the same input-to-target mapping via deep sequence of simple data transformations (layers)
Now let's Dive into how this learning happens iteratively...
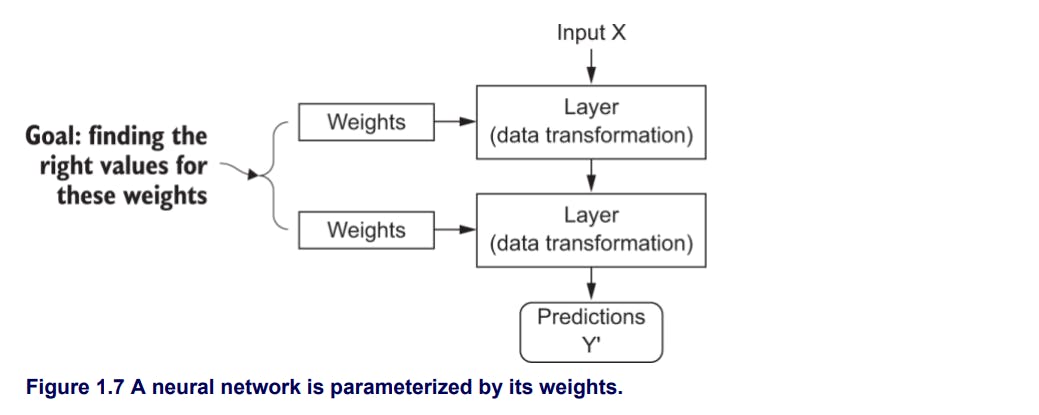
We know Neural Network is sequence of layers, when input is fed to the layer, it will be processed and the transformation of the data is stored in the layer's weights, which in essence are a bunch of numbers. Weights are also called as parameters of a layer. The big task of any model is to find the set of weights such that the network can exactly map the inputs to the targets.
Finding the correct weights or parameters of a layer is the major task, modifying the weight of one layer will affect the learning of all successive layers resulting in incorrect mapping of inputs to targets.
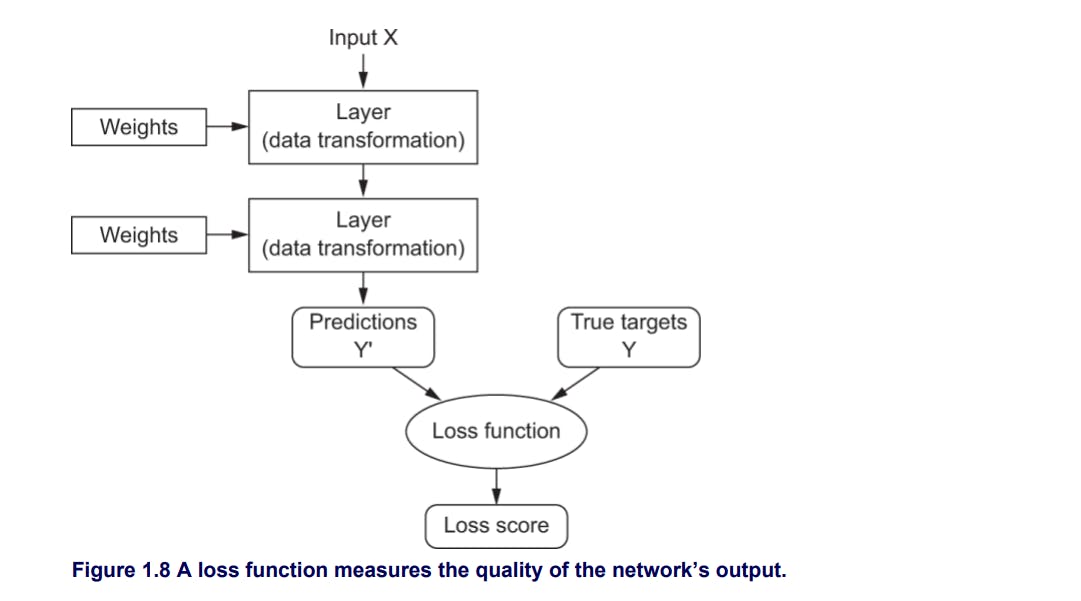
Now the concept of "Loss Function" comes, which plays a crucial role in finding the perfect weights. To control the output of neural network we need to measure how far the model's output is from the expected output. This is done by the loss function.
Loss Function : Loss function takes the predictions of the network and the true target(what we wanted the network to output) and computes the distance score, evaluates the network's performance and calculates the "Loss Score"
Now we do Iterative learning - Ready !!!!
The fundamental trick in Deep Learning is to use this Loss score as the feedback signal to adjust the weights a little, in direction that will lower the loss score for the current example.
Now the concept of "Optimizer" comes, Optimizer job is to adjust the weights based on loss score. Optimizer implements Back Propagation Algorithm.

Here is what Happens Internally:::
Initially the weights are set to the random values, so network merely implements a series of random data transformations. Naturally its output will be far from what we expect it to be, so accordingly loss score will be high. But with every example the network processes, the weights are adjusted a little in the direction that minimizes the loss score. This is the training loop, which repeated a sufficient number of times and yields weight values that minimizes the loss function.
The Network with the minimal loss function generates the outputs that are as close as they can be to the targets.
Thanks for Reading Friends, Feel free to connect with me on the Linkedin
https://www.linkedin.com/in/hariprasad-alluru-9bb6a9183/
Credits : Francois Chollet ( My motivation )